二叉查找树(Binary Sort Tree)
今天我们将学习计算机中经常用到的一种非线性的数据结构——树(Tree),由于其存储的所有元素之间具有明显的层次特性,因此常被用来存储具有层级关系的数据,比如文件系统中的文件;也会被用来存储有序列表等。
在树结构中,每一个结点只有一个前件,称为父结点,没有前件的结点只有一个,称为树的根结点,简称树的根(root)。每一个结点可以有多个后件,称为该结点的子结点。没有后件的结点称为叶子结点。一个结点所拥有的子结点的个数称为该结点的度,所有结点中最大的度称为树的度。树的最大层次称为树的深度。
二叉树
二叉树是一种特殊的树,它的子节点个数不超过两个,且分别称为该结点的左子树(left subtree)与右子树(right subtree),二叉树常被用作二叉查找树和二叉堆或是二叉排序树(BST)。
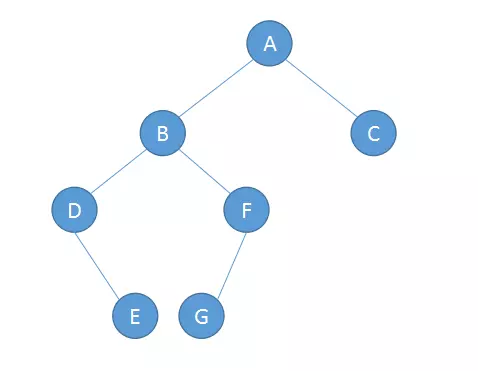
按一定的规则和顺序走遍二叉树的所有结点,使每一个结点都被访问一次,而且只被访问一次,这个操作被称为树的遍历,是对树的一种最基本的运算。由于二叉树是非线性结构,因此,树的遍历实质上是将二叉树的各个结点转换成为一个线性序列来表示。
按照根节点访问的顺序不同,树的遍历分为以下三种:前序遍历,中序遍历,后序遍历;
前序遍历:根节点->左子树->右子树
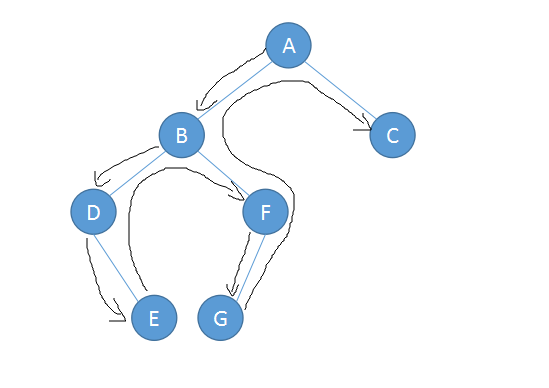
中序遍历:左子树->根节点->右子树
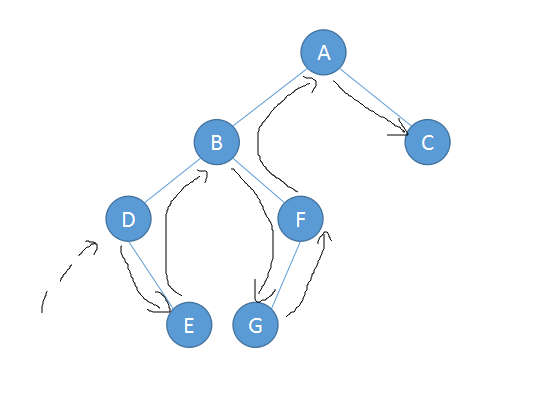
后序遍历:左子树->右子树->根节点
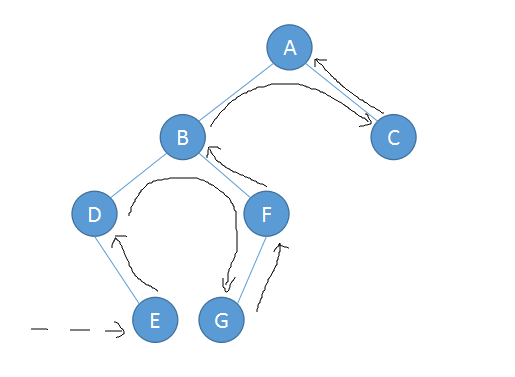
因此我们可以得之上面二叉树的遍历结果如下:
前序遍历:ABDEFGC
中序遍历:DEBGFAC
后序遍历:EDGFBCA
二叉查找树(BST)
实际应用中,树的每个节点都会有一个与之相关的值对应,有时候会被称为键。因此,我们在构建二叉查找树的时候,确定子节点非常的重要,通常将相对较小的值保存在左节点中,较大的值保存在右节点中,这就使得查找的效率非常高,因此被广泛使用。
二叉查找树的实现
根据上面的知识,我们了解到二叉树实际上是由多个节点组成,因此我们首先就要定义一个Node类,用于存放树的节点,其构造与前面的链表类似。Node类的定义如下:
1 | //节点定义 |
Node对象既保存了数据,也保存了它的左节点和右节点的链接,其中 show 方法用来显示当前保存在节点中数据。
现在我们可以创建一个类,用来表示二叉查找数(BST),我们初始化类只包含一个成员,一个表示二叉查找树根节点的 Node 对象,初始化为 null , 表示创建一个空节点。
1 | //二叉查找树(BST)的类 |
现在,我们需要为我们的类添加方法。
首先就是 insert 方法,向树中添加一个新节点,我们一起来看看这个方法;
insert:向树中添加新节点
因为添加节点会涉及到插入位置的问题,必须将其放到正确的位置上,才能保证树的正确性,整个过程较为复杂,我们一起来梳理一下:
首先要添加新的节点,首先需要创建一个Node对象,将数据传入该对象。
其次要检查当前的BST树是否有根节点,如果没有,那么表示是一棵新数,该节点就为该树的根节点,那么插入这个过程就结束了;否则,就要继续进行下一步了。
如果待插入节点不是根节点,那么就必须对BST进行遍历,找到合适的位置。该过程类似遍历链表,用一个变量存储当前节点,一层一层遍历BST,算法如下:
- 设值当前节点为根节点
- 如果待插入节点保存的数据小于当前节点,则新节点为原节点的左节点,反之,执行第4步
- 如果当前节点的左节点为null,就将新节点放到这个位置,退出循环;反之,继续执行下一次循环
- 设置新节点为原节点的右节点
- 如果当前节点的右节点为null,就将新节点放到这个位置,退出循环;反之,继续执行下一次循环
这样,就能保证每次添加的新节点能够放到正确的位置上,具体实现如下;
1 | //插入新节点 |
现在BST类已初步成型,但操作还仅仅限于插入节点,我们需要有遍历BST的能力,上面我们也提到了是三种遍历方式。其中中序遍历是最容易实现的,我们需要升序的方法访问树中的所有节点,先访问左子树,在访问根节点,最后是右子树,我们采用递归来实现!
inOrder:中序遍历
1 | // 中序遍历 |
怎么样,了解了原理,实现起来还是蛮简单的~
我们用一段代码来测试一下我们所写的中序遍历:
1 | var nums = new BST(); |
上述插入数据后,会形成如下的二叉树
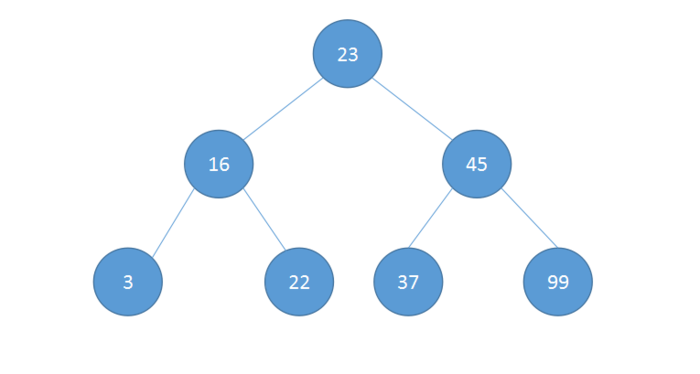
中序遍历结果如下:
1 | //中序遍历 |
preOrder:先序遍历
有了中序遍历的基础,相信先序遍历的实现你已经想出来,怎么样?看看对吗?
1 | //先序遍历 |
怎么样,看起来是不是和中序遍历差不多,唯一的区别就是 if 语句中代码的执行顺序,中序遍历中 show 方法放在两个递归调用之间,先序遍历则放在递归调用之前。
先序遍历结果如下:
1 | // 先序遍历 |
postOrder:后序遍历
后序遍历的实现和前面的基本相同,将 show 方法放在递归调用之后执行即可
1 | //后序遍历 |
后序遍历结果如下:
1 | // 后序遍历 |
二叉查找树的查找运算
对于BST通常有一下三种的查找类型:
- 查找给定值
- 查找最大值
- 查找最小值
我们接下来一起来讨论三种查找的方式的实现。
要查找BST中的最小值和最大值是非常简单的。因为较小的值总是在左子节点上,要想查找BST中的最小值,只需遍历左子树,直到找到最后一个节点即可。同理,查找最大值,只需遍历右子树,直到找到最后一个节点即可。
getMin:查找最小值
遍历左子树,直到左子树的某个节点的 left 为 null 时,该节点保存的即为最小值
1 | //查找最小值 |
getMax:查找最大值
遍历右子树,直到右子树的某个节点的 right 为 null 时,该节点保存的即为最大值
1 | //查找最大值 |
我们还是利用前面构建的树来测试:
1 | // 最小值 |
在BST上查找给定值,需要比较给定值和当前节点保存的值的大小,通过比较,就能确定给定值在不在当前节点,根据BST的特点,qu接下来是向左还是向右遍历;
1 | //查找给定值 |
如果找到给定值,该方法返回保存该值的节点,反之返回null;
1 | //查找不存在的值 |
二叉查找树的删除运算
从BST中删除节点的操作最为复杂,其复杂程度取决于删除的节点位置。如果待删除的节点没有子节点,那么非常简单。如果删除包含左子节点或者右子节点,就变得稍微有些复杂。如果删除包含两个节点的节点最为复杂。
我们采用递归方法,来完成复杂的删除操作,我们定义 remove() 和 removeNode() 两个方法;算法思想如下:
- 首先判断当前节点是否包含待删除的数据,如果包含,则删除该节点;如果不包含,则比较当前节点上的数据和待删除树的的大小关系。如果待删除的数据小于当前节点的数据,则移至当前节点的左子节点继续比较;如果大于,则移至当前节点的右子节点继续比较。
- 如果待删除节点是叶子节点(没有子节点),那么只需要将从父节点指向它的链接指向变为null;
- 如果待删除节点含有一个子节点,那么原本指向它的节点需要做调整,使其指向它的子节点;
- 最后,如果待删除节点包含两个子节点,可以选择查找待删除节点左子树上的最大值或者查找其右子树上的最小值,这里我们选择后一种。
因此,我们需要一个查找树上最小值的方法,后面会用它找到最小值创建一个临时节点,将临时节点上的值复制到待删除节点,然后再删除临时节点;
我们上面说会用到两个方法,其中 remove 方法只是简单的接收待删除数据,调用 removeNode 删除它,主要工作在 removeNode 中完成,定义如下:
1 | //删除操作 |
现在我们来删除节点试试。
1 | //删除根节点 |
成功了!
现在,我们的BST算是完整了。
我们现在已经可以利用js是实现一个简单的BST了,实际中树的使用会很广泛,希望大家能多去了解了解树的数据结构,多动手实践,相信你会有不少的收获!
作者:Cryptic
来源:稀土掘金